——————
初始版本,还需修改,建议先看视频
——————
对于绝大多数网站都可以使用RSShub去获取RSS源,但是有些小众的网站,Rsshub是不支持的,这时该怎么办?我推荐使用Feed43制作!
我相信很多人看到Feed43有些复杂的操作页面就开始心理咕噜,想要放弃,刚开始我也这样;但是一旦你认真了解Feed43的操作流程,跟着我做一遍,你会发现其实不难!
流程
我使用我的网站GotBook作为演示,先打开网站的首页;
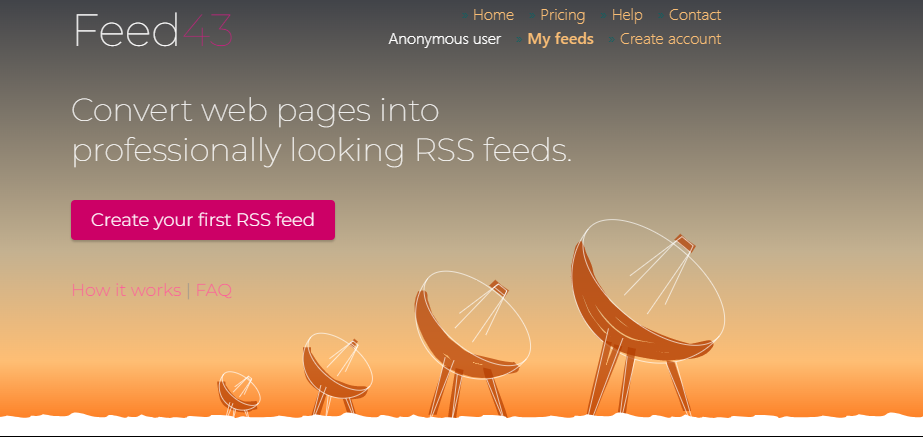
然后打开Feed43,点击Create your first RSS feed,创建新的RSS Feed;
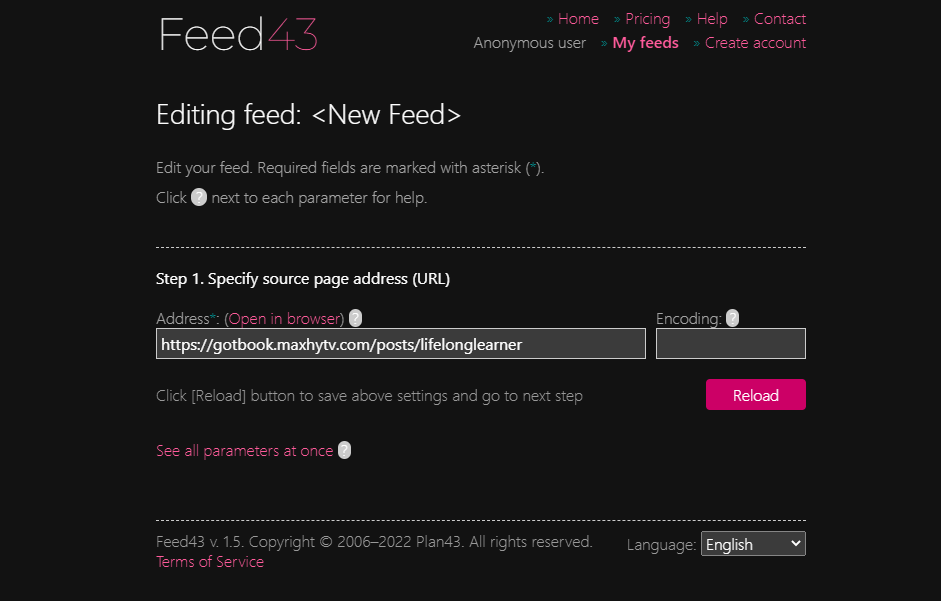
复制我的网站链接并粘贴到Feed43地址框中,Encoding不需要填写,点击Reload;如果在页面上出现Html源代码,说明第一步没有出现差错
然后到了关键步骤,填写Html字段;查找字段需要看到网站GotBook页面,例如”将网页高亮以及批注自动保存到Obsidian中“,然后在Html代码中找到这段标题文本;
提示:一般标题文本在Feed43的html源码中会被标记红色
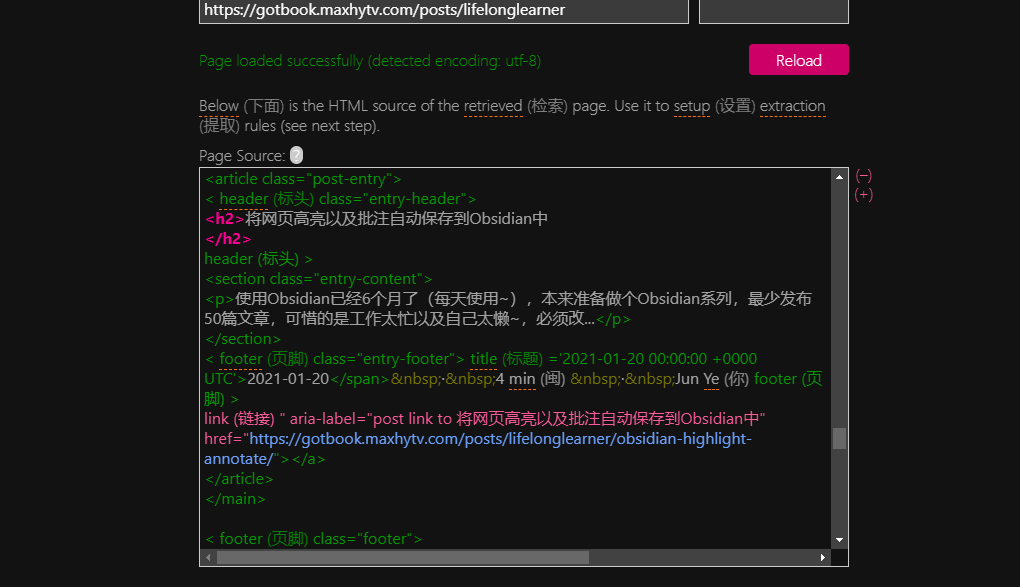
现在在”将网页高亮以及批注自动保存到Obsidian中“周围找到需要包含标题、链接、时间的html字段;
|
|
现在我们需要将字段标题、链接、时间、摘要用{%}代替,并将多余字段用 {*} 代替,这个多余字段需要在使用制作过程中慢慢尝试,然后代码变成:
|
|
将代码输入到 Define extraction rules,不用修改Global Search Pattern (optional)里面内容,接下来点击Extract
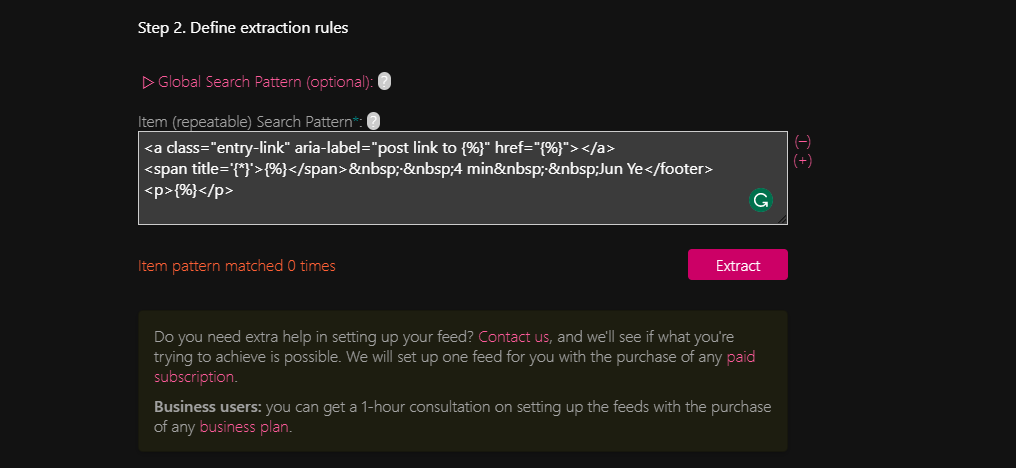
如果出现类似下面语句,就说明feed制作成功;如果不是就需要重新查找字段; ![[Pasted image 20220429200539.png]]
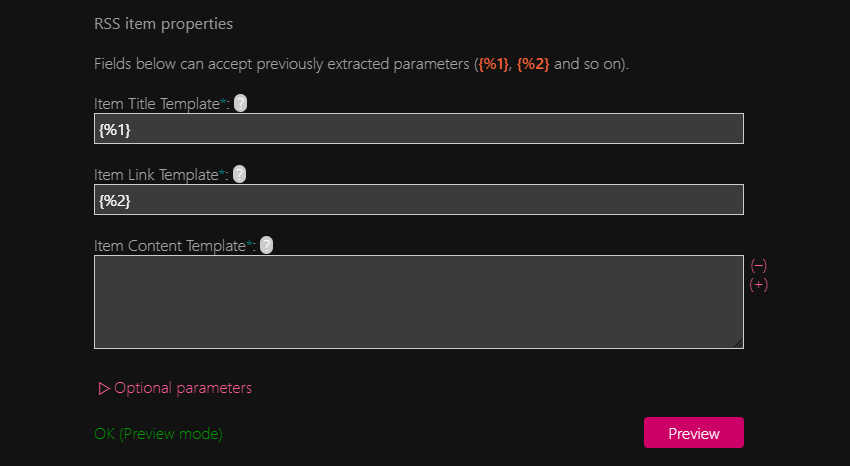
看到上图,应该发现代码里面出现{%1}、{%2},这个是代表文章标题和文章链接,接下来我们需要做的是将{%1}、{%2}填入RSS item properties,完善RSS爬取信息;然后点击preview
最后,我们的RSS链接就制作完毕,然后在页面的最下方可以复制RSS链接
|
|
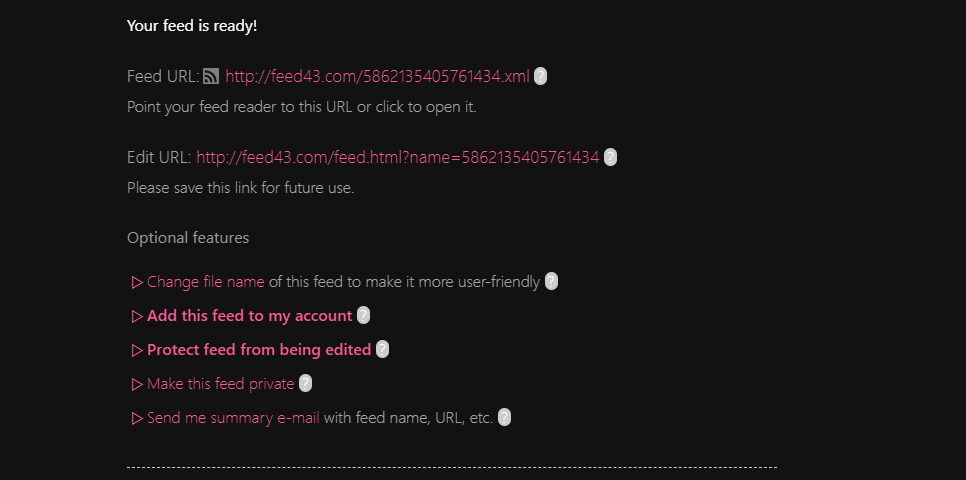
Feed43不需要付费或者懂得太多的html知识,模仿上面的流程基本上可以抓取到90%以上的页面。但是Feed43也有他的缺陷,例如不能抓取全文,但是对于信息的获取还是挺有帮助的。